What is Web Scraping?
Imagine a process where you want to acquire data from any resource or website. The first thing that a developer thinks of does the source has a developer account and it provides an API to get the required information, but in the majority of cases, there are no dev accounts and no APIs available, which makes it difficult to acquire information. Here web scraping comes to the rescue. In web scraping, we analyze the HTML of a website and write the data extraction logic programmatically and store the information in either DB or export the data as a spreadsheet or send the data as a part of the API
Tools & Technologies used for web scraping
Python language used for web scraping. In Python, we have the Scrappy framework and a library called BeautifulSoup widely used to get solutions for web scraping. Selenium acts as a mode to mimic browsers in case we need to provide user credentials to log in to any website/application, or it is used in cases where the data is loaded only when we scroll to the bottom and extract data. Using Selenium, we can provide click events and mouse movements that mimic the user accessing the website or application.
Step-by-step process of Web scraping
- The first step will be to Identify the target website from where we want to extract the data in the case. I have chosen Flipkart to scrape the reviews of any product.
- Then we need to collect the URLs of the pages which you want to extract data from.
- Now we need to make a request to these URLs to get the HTML of the page to make the request. We can use the requests library in python.
- After this, you will have the HTML page of the URLs as text then. We need to use the Beautiful soup library, with the help of which we can easily track the location of the desired data and extract(scrape) only that data out of the HTML.
- Now we can save the data in a JSON, CSV file, or another structured format.
- Challenges in Web Scraping
A- Although it is easy to scrape the data for small projects. There are some challenges in most cases, such as tackling the change in the layout of the webpage, which means if the layout of the webpage changes, the logic we have implemented to get the structured data should also be changed accordingly.
B- Since web scraping requires a lot of requests made to a server from an IP address. The server may detect too many requests and block the IP address to stop further scraping. Proxies rotate the IP address, which helps to avoid blocking the scraper and any issues. It also helps hide the machine’s IP address as it creates anonymity.
C- Most websites use CAPTCHA to detect bot traffic. By using CAPTCHA-solving services, we can bypass this extra layer. There are a few CAPTCHA-solving services:
Implementing Web Scraping in Python with BeautifulSoup
So here we will see the implementation of building a simple web app using flask to scrape the reviews of the products listed on the Flipkart webpage:
Here the first steps will be to install and import all the required libraries:

After successfully importing the required libraries, we will write the steps to fetch the reviews in the structured format; below code is to fetch the reviews section data; we just have to pass the product name in the search string from the frontend:

To select the class of any object on the HTML, you have to go to the HTML page and right-click on the page anywhere, like the below snapshot:
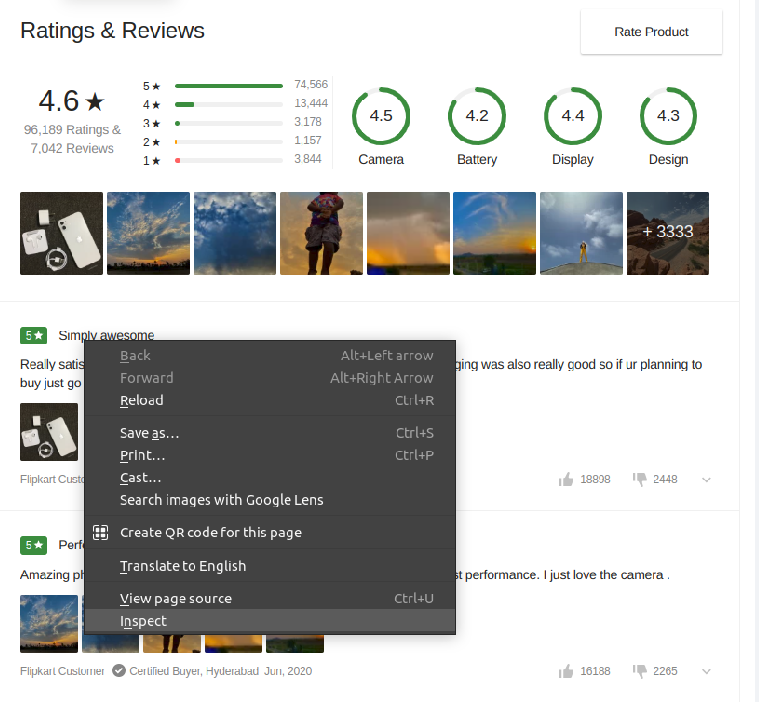
And click on the inspect option; after this, a dev page will open. You just have to hover the mouse over the object to see the class of that object on the dev page; below is the example snapshot attached:

So as you can see, by hovering over the review, it is showing “_16PBlm” as the class name. So I have taken that as the class name in the code.
In the above code, the first step is going to the Flipkart searched product webpage, such as if you search for iPhone in the search box from the frontend. It will go to the below page internally:
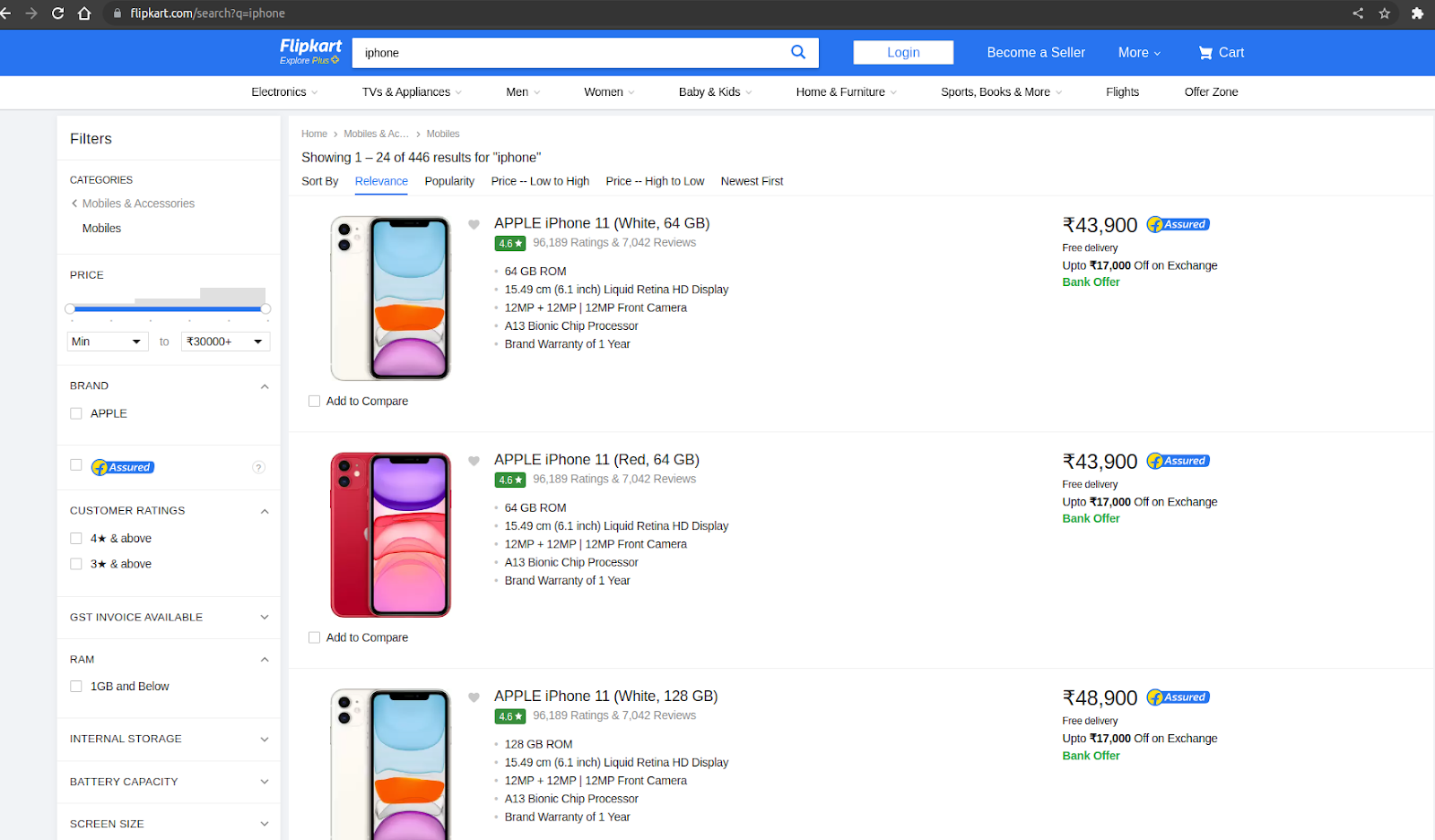
And will select the first product to fetch the reviews:
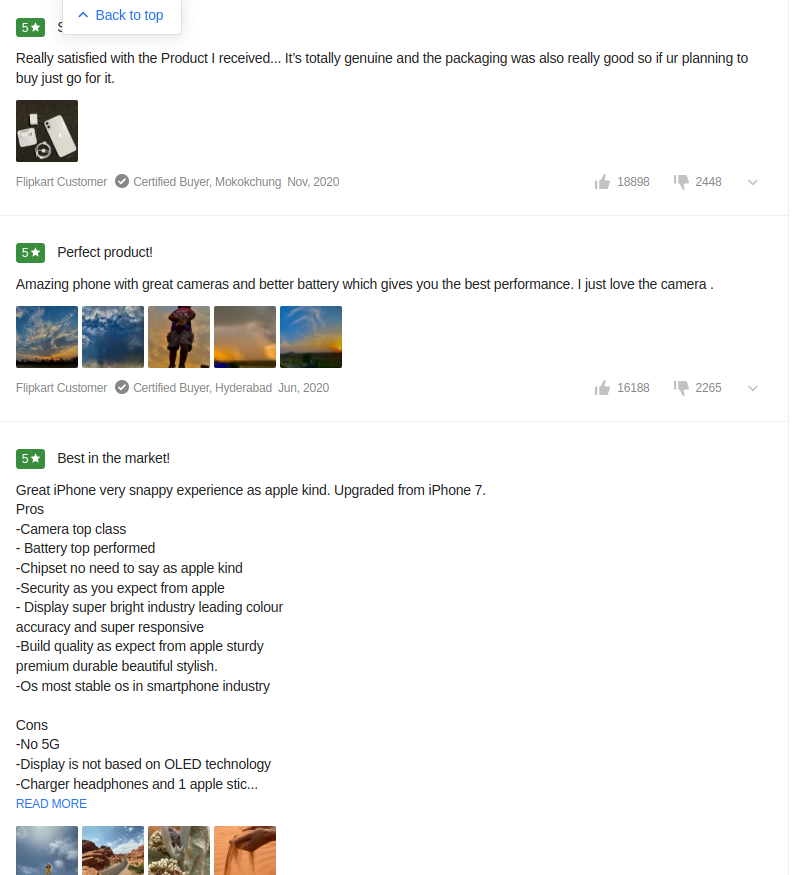
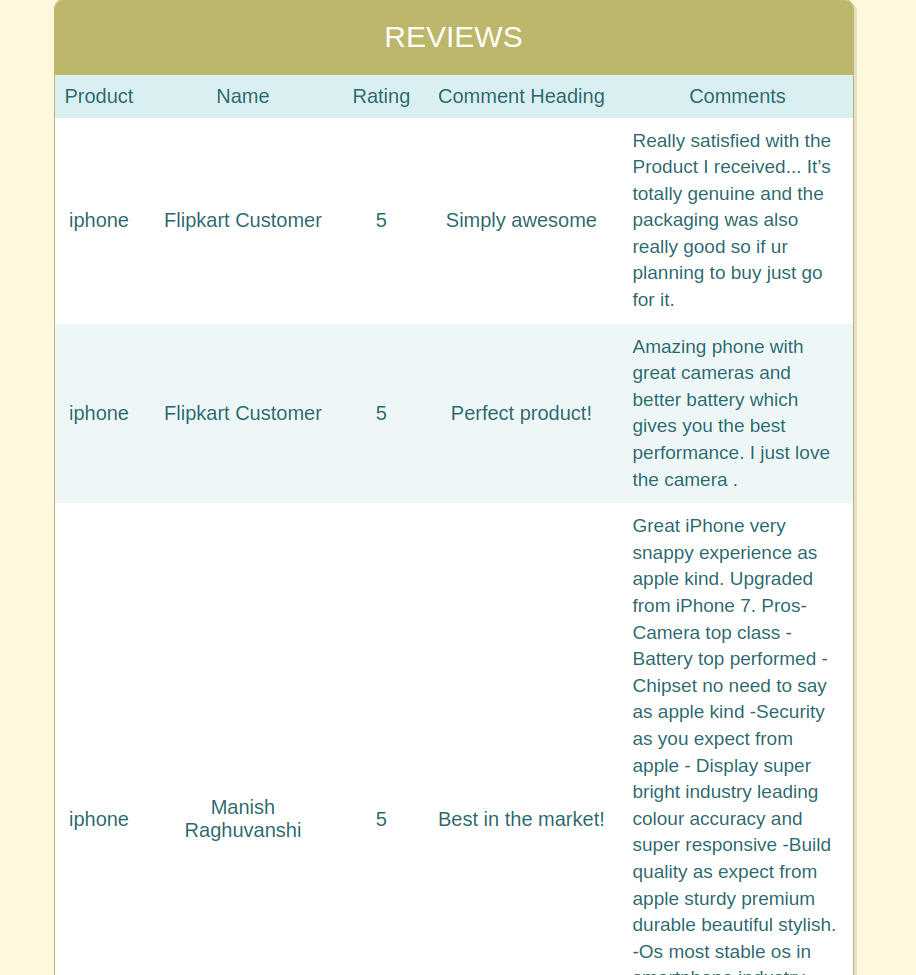
The above image has the reviews that will be scrapped in a table with the header “Product, Customer Name, Rating, Heading and Comment” in a structured format.
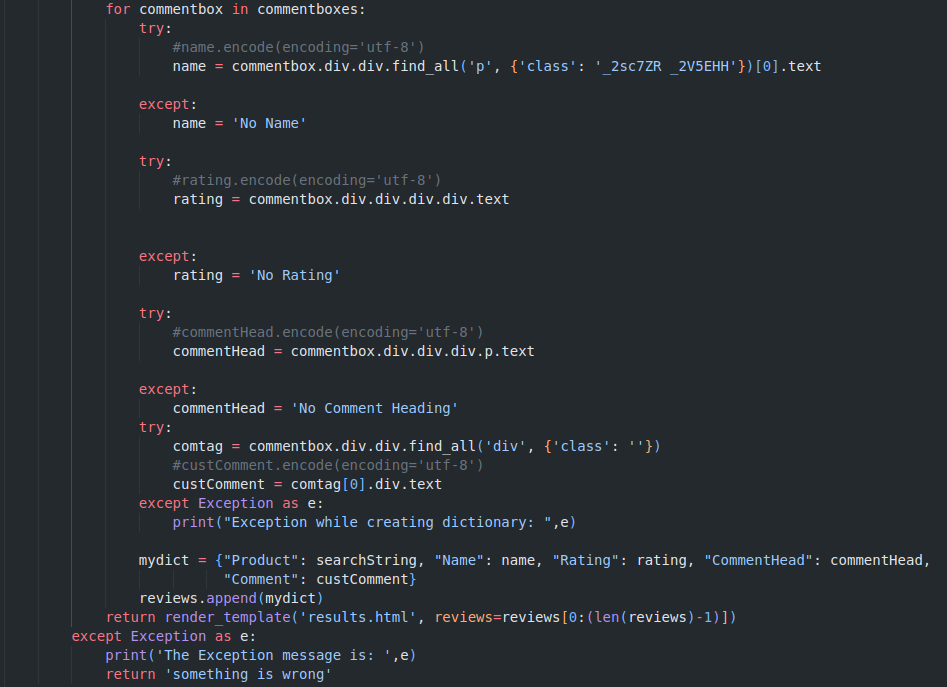
Moving further, we will add the respective data to the table and handle the exceptions that may occur. If any of the above fields are blank and the below code is to add the data in the table while handling the exceptions:
Now, we will run this code and will get the below output:
Now we can see that our application is running on the localhost http://127.0.0.1:5000. By clicking on this HTTP link, we will redirect to the webpage :
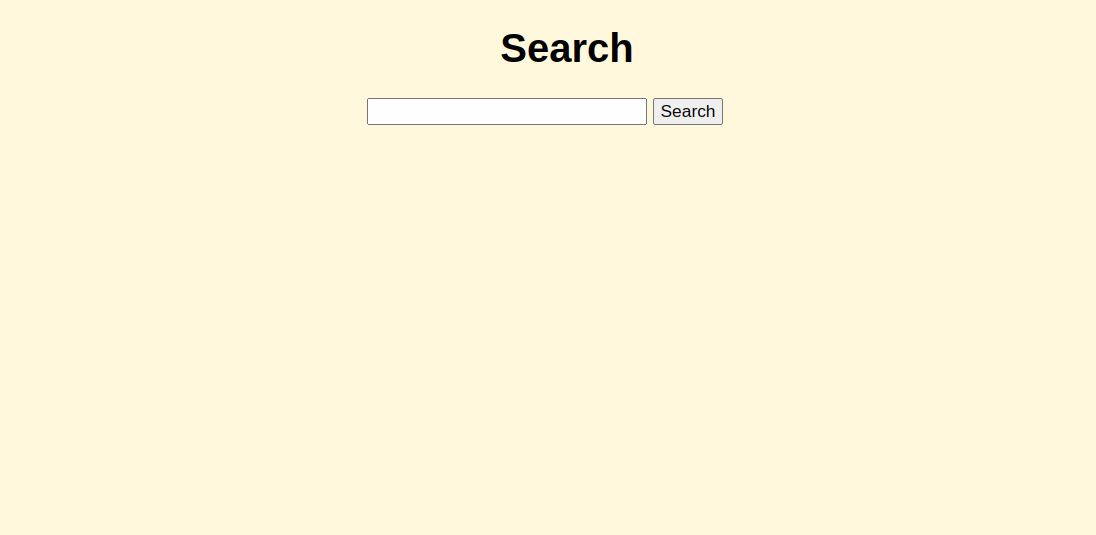
So here, in the search box, we can search with the name of the product, of which we have to scrape the reviews.
The below snapshot is the Output of the search with the product name iPhone. This will fetch you real-time reviews from the webpage:
Web scraping services offered by Thinkitive
At thinkitive, we have worked on various projects in different domains and built browser extensions to support web scraping. We have a framework that speeds up the time to scrape any resource. We ensure the scraper is not blocked by taking all possible precautions. At Thinkitive, we have built scrapers that serve thousands of requests simultaneously. We have scrapers built for all types of websites, like dynamic web pages, which are rendered infinitely.
For any questions and inquiries related to web scraping services or if you’re looking to hire Python developers, please contact us.





Very nice post. I just stumbled upon your blog and wanted to say that I’ve really enjoyed browsing your blog posts. In any case I’ll be subscribing to your feed and I hope you write again soon!
Cool. I spent a long time looking for relevant content and found that your article gave me new ideas, which is very helpful for my research. I think my thesis can be completed more smoothly. Thank you.
Wonderfսl, wһat a webѕite it іs! This website provides ᴠaluable
informatiߋn to us, keep it uⲣ.