Write Dynamic XPath for test automation with Selenium WebDriver.

Discover the power of dynamic XPath for efficient test automation with Selenium WebDriver. This introductory guide will equip you with the knowledge and techniques to write robust and adaptable XPath expressions, enhancing your automated testing capabilities altogether.
To begin discussing Xpath, It’s essential first to understand what a locator is.
What is Locator:
In Selenium, a Locator is an address of an element that helps the automation script to locate an element uniquely on a web page.
During test automation, Selenium utilizes locators to interact with web elements by performing actions on them and extracting data from them. In addition, this allows Selenium to simulate user interactions with a web page and verify that the expected behavior is produced.
Suppose you have easy-to-use unique IDs and classes for web elements. However, sometimes it can be challenging to find the right locator due to the complexity of the webpage. Let’s explore the different types of locators available in Selenium.
What locators are supported by Selenium?
Selenium uses various types of locators to precisely and accurately identify web elements. Following are the types of locators used:
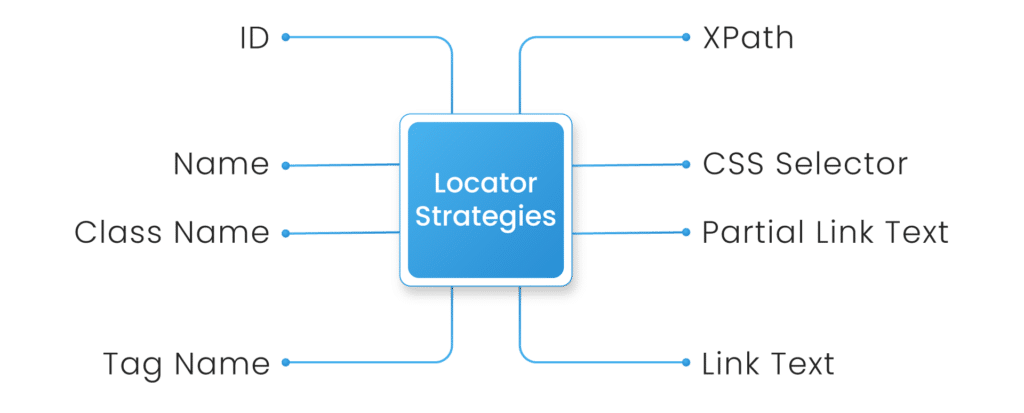
- ID: Find elements by Unique identifier.
- Name: Find elements by “Name” attribute value.
- Class Name: Find elements by CSS class name
- Tag Name: Find elements by their HTML tag name.
- Link Text: Find link elements by exact text.
- Partial Link Text: Find link elements by partial text.
- CSS Selector: Find elements by matching attributes using CSS selectors.
- XPath: Find elements using the XPath expression to navigate the webpage DOM structure.
What is DOM?
First thing to remember, the Document Object Model (DOM) is a way for computer programs to understand and manipulate the structure of a web page. It represents the web page as a tree-like structure of objects, which can be accessed and modified using programming languages like JavaScript. This also allows developers to create dynamic effects, modify content, and respond to user interactions on web pages.
What is XPath in Selenium?
XPath, a locator generally used in Selenium WebDriver, provides a robust way to navigate the HTML structure of web pages. It enables locating elements on a page, beneficial when other options are unavailable. XPath also allows for the traversal of the DOM tree, smoothing the identification of elements that may not be visible on the page. Furthermore, its adaptability has made it an essential tool for web automation testers and developers.
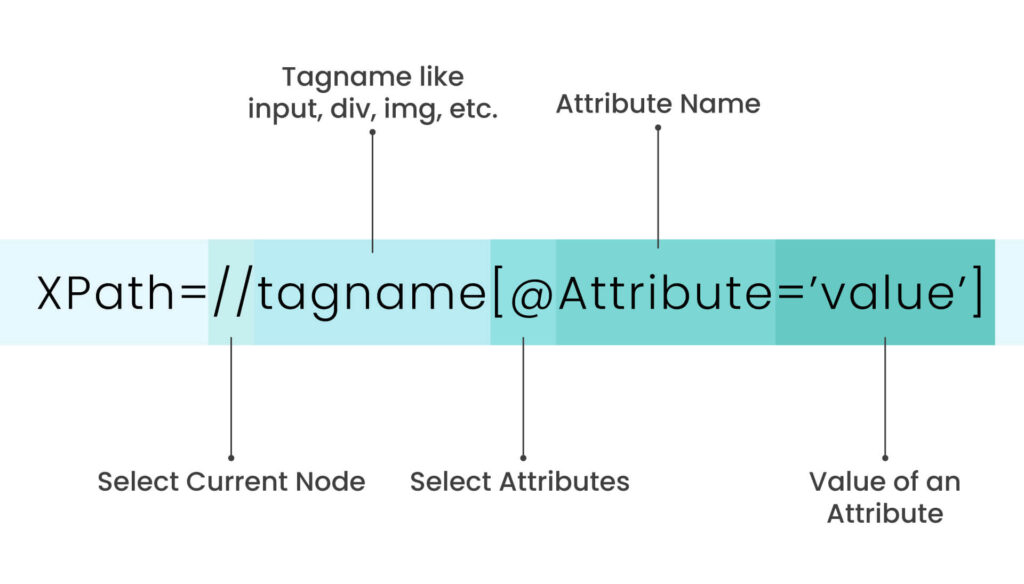
Following are the different Approaches to Find Elements Using Dynamic XPath in Selenium :
1. Absolute XPath
- XPath’s “absolute” method is a direct approach to locating elements.
- The main disadvantage is that if an element’s path changes, the XPath will no longer function and must be adjusted, which in fact can be challenging and time-consuming.
- Absolute XPaths may be unreliable because browser inconsistency or page structure changes can cause unexpected issues. This method begins with a single forward slash (/) to indicate that the search begins at the document’s root node.
Example:
/html/body/div[2]/div/div/div[2]/div/div/form/div[1]/div/div[1]/input
2. Relative XPath
- Relative XPath is a way to find specific elements on a webpage by starting from a specific node rather than the beginning of the page.
- Relative XPath not only makes finding the exact element we want to target easier but also can be used on different websites with minimal changes.
- It is also less likely to cause errors and is more flexible, making it easier to locate elements even if the page structure changes.
- It starts with a double forward slash (//), indicating that the search will begin from the document’s current node rather than the root node.
Example:
//input[@id=’txtLoginEmail’]
There are multiple ways to Create Dynamic XPath in Selenium:
- USING PROPERTY VALUE PAIRS:
//TAG_NAME[@PROPERTY_NAME, ‘PROPERTY_VALUE’]
Example:
//button[@id=’btnLogin’]
- USING MULTIPLE PROPERTIES:
//TAG_NAME[@PROPERTY_NAME_1=’PROPERTY_VALUE_1′][@PROPERTY_NAME_2=’PROPERTY_VALUE_2′]We can add as many property value pairs as possible.
Example:
//button[@id=’btnLogin’][@type=’Button’]
- USING HIERARCHY, THE PARENT ELEMENT
//PARENT_TAG_NAME[@PARENT_PROPERTY_NAME_1=’PARENT_PROPERTY_VALUE_1′]//CHILD_TAG_NAME[@CHILD_PROPERTY_NAME=’CHILD_PROPERTY_VALUE’]
Example:
//div[@class=’loginBox’]//a[@id=’sign_in_link’]
- ABSOLUTE INDEX – IN SITUATIONS WHERE A XPATH RETURNS MULTIPLE ELEMENTS.
Example: – Search results on eBay or any shopping site.
(//TAG_NAME[@PROPERTY_NAME, ‘PROPERTY_VALUE’])[1] :- THIS WILL RETURN THE FIRST ELEMENT OF THE GROUP
(//TAG_NAME[@PROPERTY_NAME, ‘PROPERTY_VALUE’])[2] :- THIS WILL RETURN THE SECOND ELEMENT OF THE GROUP
Example:
(//div[@class=’loginBox’])[1]
- USING TEXT DISPLAYED IN THE HTML TAGS
//TAG_NAME[text()=’text_displayed’]
Example:
//a[text()=’Sign In’]
- USING PARTIAL PROPERTY VALUE COMPARISON
//TAG_NAME[contains(@PROPERTY_NAME, ‘PROPERTY_VALUE’)]
Example:
//a[contains(@class,’loginDiv’)]
- IN CASE OF PARTIAL TEXT COMPARISON
//TAG_NAME[contains(text(), ‘PARTIAL_TEXT’)]
Example:
//a[contains(text()=’Sign’)]
Dissolve a myth in the software testing industry that XPath takes more time to process than CSS selectors in Selenium WebDriver:
- Myth: Many people in the software testing industry believe that XPath locators take more time to process than CSS selectors in Selenium WebDriver.
- Reality: A case study has shown no significant difference in execution time between XPath and CSS selectors in Selenium WebDriver.
- Factors: The performance of selectors in Selenium WebDriver depends on various factors, such as the complexity of the selector, the size of the DOM, and the browser in use.
- Recommendation: Performance tests and benchmarks must be performed to determine the most effective selector type for a specific use case.
- Conclusion: The belief that XPath takes more time to process than CSS selectors in Selenium WebDriver is a myth and can mislead software testers.
Conclusion
Writing dynamic XPath expressions in Selenium WebDriver is an essential skill for automated testing. However, it involves understanding how web pages are structured using HTML and being able to find unique properties of elements on a page to create reliable and efficient XPath expressions. By having this skill, testers can create automated tests that are more dependable also easy to maintain over time.
The key takeaways from the above statement are:
- Selenium supports 8 locators that can be used to identify web elements on a web page.
- The “id” locator is one of the most reliable and fast methods of element recognition because it is usually unique on a given web page.
- CSS selector and XPath are robust locators that can identify dynamic elements on a web page.
In conclusion, these key takeaways are helpful for software developers and testers who work with Selenium to automate web testing. Additionally, by using the appropriate locator strategies, they can create practical and efficient test scripts to identify and interact with web elements on a web page.





Hi there! This post could not be written any better! Looking at
this post reminds me of my previous roommate!
He always kept talking about this. I will send this information to
him. Fairly certain he’s going to have a good read. Many thanks for sharing!
Wow, that’s what I was looking for, what a information! existing here at this webpage, thanks admin of this
web page.
Hello, I enjoy reading through your article post. I like to write a little comment to support you.
Hello there! I just would like to offer you a big thumbs up for the great information you’ve got right here on this post.
I’ll be returning to your site for more soon.
If you are going for best contents like me, only pay a quick visit this web site all
the time because it gives feature contents, thanks
Fantastic website. A lot of useful information here. I am sending it to a few pals ans additionally sharing in delicious.
And of course, thank you for your effort!