
Automatic Speech Recognition and creating SOAP Notes
Industry
Healthcare, Speech Recognition, OCR
Technologies
Python, Angular, TypeScript, REST, SOAP, Web Services
Client Requirements
The client is a USA-based specialist group that provides the best-personalized care for infectious diseases. Healthcare communication platform that connects care teams and engages patients in real-time. In healthcare, data collection allows health systems to create holistic views of patients, personalize treatments, advance treatment methods, improve communication between doctors and patients, and enhance health outcomes. The client wanted to record the encounter with the patient and save the details of the encounter to the EHR. The client wanted to develop a speech-to-text application with the most significant impact. The benefits are time savings and better productivity, as medical professionals usually spend much of their day doing paperwork.
Thinkitive Solution
Thinkitive’s business analysts and subject matter experts started with the requirement analysis ( Discovery) phase. The thinkitive team took multiple calls with the client and created a detailed SRS requirement document and low-fidelity wireframes. Thinkitive established a team of professionals with expertise in Artificial Intelligence development. The thinkitive team leverages speech recognition-based architecture and develops speech recognition software that enables the recognition and translation of spoken language into text through computational linguistics. It enables real-time and batches transcription of audio streams into text.
-
Speech Data:
Data containing the Audio files to preprocess the audio file is converted into an array using the Libros library. The sampling rate at this moment plays a vital role in defining how many data points of the speech signal are measured per second. Therefore, sampling with a higher sampling rate results in a better approximation of the actual speech signal.
-
Transcription:
Text preprocessing is done as below and provided to the model:
1. Removing special characters
2. Extracting all characters
3. Creating vocabulary of all characters and assigning a numeric value to vocabulary
4. Vocabulary converted to the JSON format
-
Feature Extractor:
Feature Extraction aims to reduce the number of features in a dataset by creating new features from the existing ones and then discarding the original features. It can reduce higher dimension features to lower dimensions. These new reduced sets of features should then be able to summarise most of the information in the original set of features to reduce the number of trainable features using feature extraction.
-
Tokenizer:
Tokenization is splitting a phrase, sentence, paragraph, or entire text document into smaller units, such as individual words or terms. Each of these smaller units is called a token. The tokens could be words, numbers, or punctuation marks.
Solution Highlights
Providers would need to spend a large percentage doing paperwork and always have a margin of error when done manually. To make it easier for health providers, the system allows the provider to record the conversation between provider and patient, which Is converted into text using speech to text model. The provider can dictate notes much faster than typing them. This Speech recognition application is the process by which a system maps an acoustic speech signal to some form of the abstract meaning of the speech. The libraries, such as Libros, pydub, and sound files, are used to preprocess the audio files in the required format. Text Preprocessing is done by removing special characters, Extracting all the characters, creating a vocabulary of all characters, assigning a numeric value to vocabulary, and vocabulary converted to JSON. After preprocessing, the preprocessed data passed to the processor contains a feature extractor and tokenizer that converts data into the specific format required to train the model. Feature extraction and pattern matching techniques play an essential role in the speech recognition system to maximize the speech recognition rate of various persons. The training was done on processed input values and predictions on test preprocessed data, and evaluation was done using evaluation metrics word error rate. Speech-to-text APIs are application programming interfaces that perform speech recognition to transcribe voice into written text. This Application allows the stakeholder to choose the audio wave file and see the output as text.
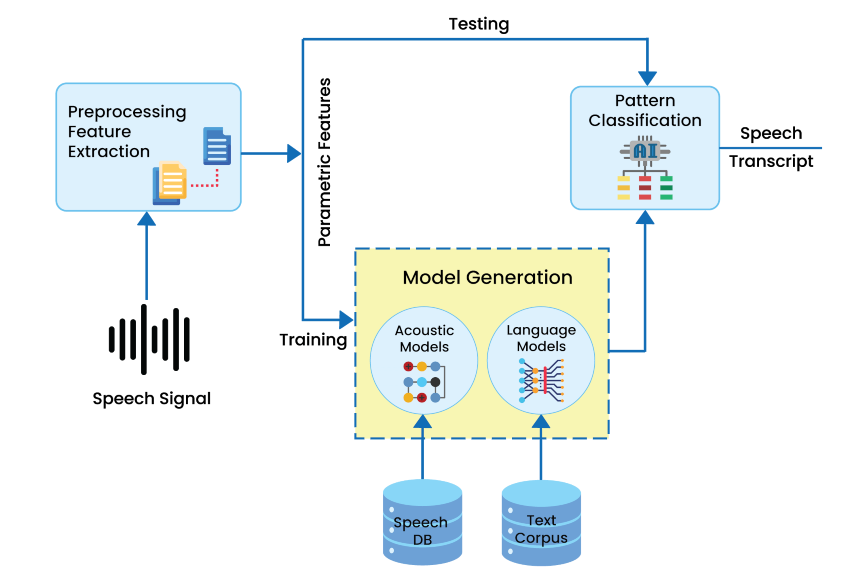
-
Pre-processing/Digital Processing:
The recorded acoustic signal is analog. An analog signal cannot directly transfer to the ASR systems. So these speech signals need to transform into digital signals and then only they can be processed. These digital signals are moved to the first-order filters to flatten the signals spectrally. This procedure increases the energy of the signal at a higher frequency. This is the preprocessing step.
-
Feature Extraction:
The feature extraction step finds the set of parameters of utterances that have an acoustic correlation with speech signals. These parameters are computed through the processing of the acoustic waveform. These parameters are known as features. The main focus of the feature extractor is to keep the relevant information and discard irrelevant ones.
-
Acoustic Modelling:
Acoustic modeling is a fundamental part of the ASR system. Training establishes co-relation between the essential speech units and the acoustic observations in acoustic modeling. Training of the system requires creating a pattern representative of the features of the class using one or more patterns that correspond to speech sounds of the same class.
-
Language Modelling:
A language model contains the structural constraints available in the language to generate the probabilities of occurrence. It induces the probability of a word occurrence after a word sequence. Speech recognition systems use bi-gram, trigram, and n-gram language models for finding correct word sequences by predicting the likelihood of the nth word, using the n-1 earlier words. In speech recognition, the computer system matches sound with word sequence. The language model distinguishes words and phrases that have similar sounds.
Value Delivered
-
Enable stakeholders to extract text from audio files.
-
Useful in the medical field, like maintaining electronic medical records (EMR) and medical transcription.
-
Less time spent taking notes and filling out charts means more time to help patients.
-
Creates a digital record of a patient’s history which can be later searched instead of spending time searching countless paper documents.
-
Instead of manually typing long texts for articles, documentation using a speech-to-text API to dictate your words and get them written as the text will ease work and accelerate workflow.