Supporting IoT Applications with Cassandra
Cassandra Optimisations for IoT Applications
Overview:
Apache Cassandra is a distributed NoSQL database designed to handle huge amounts of data, providing extensive scalability and data availability options. This blog post will briefly introduce Cassandra and its key features, highlighting ways to efficiently model it. We will also get familiar with a practical approach to query Cassandra asynchronously using Java.
Why choose Cassandra?
One of the key attributes of an IOT based application is its ability to persist data. There may be around 10,000 to 100,000 records being pushed to the application every second in a real-time scenario. Persisting this data and doing manipulations over it can be quite challenging. Organizations are also interested in using this data for mining, which helps them gain vital insights and make informed decisions. Cassandra tends to provide an ample number of features that apply to this scenario.
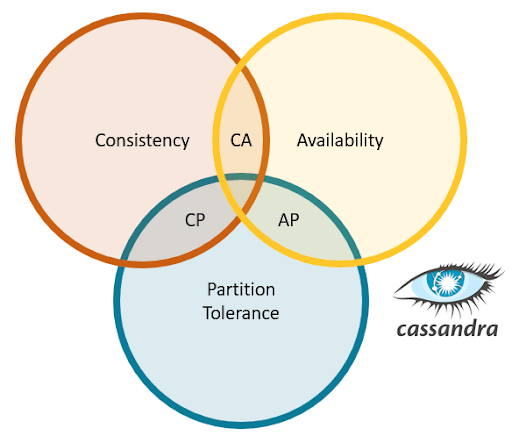
Fig 1: Cassandra (CAP Theorem)
- Cassandra writes is very efficient, which allows it to handle heavy loads.
- It provides a good modeling platform for time series data since Cassandra’s individual rows can have a dynamic number of columns.
- Cassandra allows tuning its consistency hence providing an option to choose consistency or availability (CAP theorem).
- Cassandra can be easily upscaled or downscaled as it was designed to support the dynamic addition/removal of data nodes.
- Cassandra also provides features like storage compression, Time-to-Live, etc.
Cassandra Data Modelling:
Cassandra needs to be modeled according to queries planned to be executed on it to achieve good performance. Writes are efficient and optimized in Cassandra. If you can improve read queries by increasing the number of writes, it’s a good tradeoff. Compared to writes, reads are difficult to tune. Denormalization of data is important to improve read performance and increase data availability. Storage space is a considerably cheap resource (compared to CPU, memory, disk IOPs or network) and Cassandra takes advantage of that.
Key Points:
- Cassandra data modeling’s de facto to model it around query patterns and not around data objects or relations. Identify query patterns specific to the business problem at hand.
- Data duplication is required to improve read performance and ensure data availability.
- Data needs to be distributed evenly across the C* cluster. Each node must share the same amount of data.
- Minimizing queries that require reading from multiple partitions is very important. Create tables that will only require to read data from a single partition.
Querying Cassandra Asynchronously:
Fetching historical time-series data is cumbersome since it is very taxing on the network and CPU I/O. Clients sometimes require generating reports based on historical data and our applications can provide that efficiently. It is important to understand how Cassandra reads and writes data to query it efficiently. Let us walk through different ways of querying Cassandra asynchronously.
A simple approach:
The session.execute internally issues executeAsync() and returns the result by immediately calling get method on it. Let’s go through some sample code (For brevity, keeping it simple and concise)
1. Executing the query:
ResultSetFuture future = session.executeAsync(query);
2. Doing some operations on the result:
while (!future.isDone()) {
System.out.println(“Executing Queries…..”);
}
//blocking operation
ResultSet rs = future.get();
The invocation of get() method on the future is a blocking operation. The executing thread is blocked if the future is still incomplete. We can also allocate a timeout to the get operation. If the results are not available within the specified time, we can abandon the execution.
try {
ResultSet rs = future.get(5, TimeUnit.SECONDS);
// do something
}
catch (TimeoutException e) {
e.printStackTrace();
}
// do something else
We can timeout the get operation if it’s taking too long to complete. This approach doesn’t guarantee the fetching of results.
A better approach:
Future is quite limited since it does not allow us to wait for a result in a non-blocking manner. A better option would be the Listenable Future interface. It is a part of Google’s Guava library. It provides registration of a callback to the execution of a future. ResultSetFuture of the Cassandra drives uses Listenable Future internally. Futures is a utility class from the Guava library which provides numerous methods to work with Listenable Future. We will take advantage of that as well. Following is code snippet exhibiting Futures.addCallback() method :
ResultSetFuture future = session.executeAsync(query);
Futures.addCallback(future, new FutureCallback<List<TimeseriesData>>() {
@Override
public void onSuccess(@Nullable List<TimeseriesData> result) {
// do something with the result
}
@Override
public void onFailure(Throwable t) {
System.out.println(“Execution ended abruptly”);
}
});
The addCallback method registers separate success and failure callbacks, which can be run when the future will be completed or if already completed. The method internally calls
addCallback(future, callback, MoreExecutors.sameThreadExecutor()).
Noticed how the task is internally submitted to sameThreadExecutor()? This will be the client thread that has the responsibility to execute the task. This will suffice for lightweight callbacks, but it’s recommended to use an external ExecutorService. Futures provides an overloaded addCallback() method, which allows us to pass an ExecutorService
Futures.addCallback(ListenableFuture<V>, FutureCallback<V>, Executor)
Another functionality provides by the Futures class is Futures. Successful list(). This enables us to result in the result of successful futures as a List. We can also use the in completion order() method to return the result of futures in the complete order. This will allow us to retrieve results as they are available.
Takeaways:
- We should take advantage of the non-blocking nature of the Cassandra driver through its executeAsync() method.
- Google’s Guava library provides powerful utilities to manipulate asynchronous operations and work with Listenable Future.
- We can also chain async operations using the Future class for extended computations.
I am a software engineer @Thinkitve. We are many enthusiast developers who are dedicated to following our clients’ best practices, enabling them to minimize cost and maximize efficiency.




