Let’s talk about Clustering (Unsupervised Learning)
What is a cluster?
Simple Definition:
A collection of similar objects to each other.
Slightly Complex Definition:
A connected component of a level set of the probability density function of underlying (and unknown) distribution from which our data samples are drawn.
You are posed with a problem to solve. What you have is a large amount of data represented in a lot of dimensions. The data can not be read or understood by looking at it raw by a human.
Even before you start defining your problem (hypothesis), you need to understand the data, perform an EDA on it. There are multiple ways to do it.
What would be the first thing you do?
A. Perform Clustering
Perfect! Clustering is the right way of identifying interesting parts of data by grouping it.
What is clustering?
Clustering is a process of grouping a sample of data into smaller similar natural subgroups called clusters. Below you can see a plot of the iris dataset applied with the K-Means clustering algorithm.
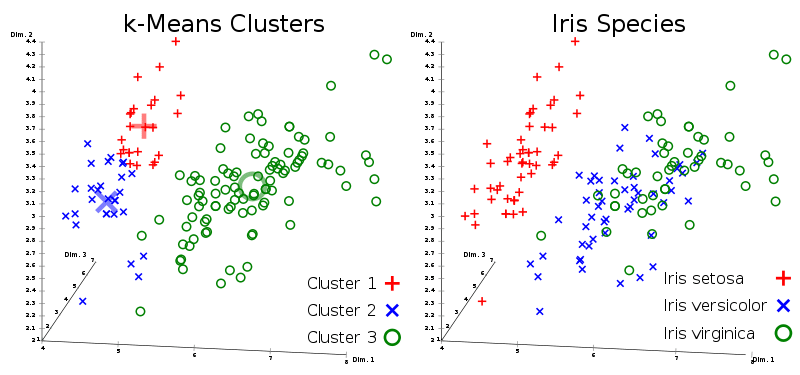
What would be your first choice of a clustering algorithm?
A. K-Means, K-Mediods, Hierarchical, Spectral, DBSCAN ?
Hold On! Not so fast.
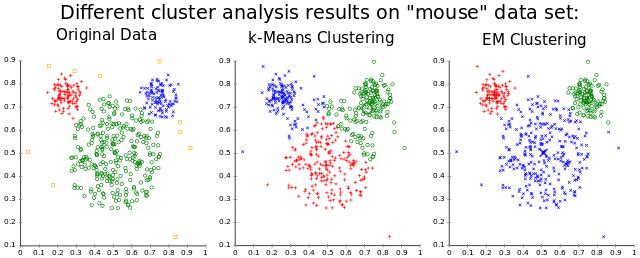
Clustering means different things to different applications. The results may vary according to the data it sees. Hence the choice of the algorithm also depends on data. If you are dealing with image data, you would want to be careful while selecting an appropriate algorithm because most clustering algorithms are instance-based learning methods and are expensive to compute and require a lot of memory. The more data you show to the algorithm, the more size it occupies.
These algorithms take a relatively long time to converge, time complexity (BigO) of some of these algorithms have complexities of O(n log(n)), few alternatives which provide linear complexities also exist.
What is the input to a clustering algorithm?
A. Just data.
Clustering is an unsupervised technique, i.e., the input required for the algorithm is just plain simple data instead of supervised algorithms like classification. Supervised algorithms require data mapped to a label for each record in the sample.
After you have finalized an algorithm and fed data to it, what would be next? To determine a good cluster.
What is a good cluster?
A cluster is good if it separates the data cleanly by that we mean it clearly identifies data which belong to different clusters and assigns cluster labels to it.
Some technical points to note are:
- The inter-cluster similarity should be high (distance should be less)
- The intra-cluster similarity should be low (distance should be more)
If the above properties are satisfied, we can say that the algorithm has resulted in good clusters.
How is similarity measured among data points?
The measure used to define similarity or dissimilarity is the distance among the spatial co-ordinates between two points.
There are multiple options for this parameter :
- Euclidean Distance
- Manhattan Distance
These are the two popular choices, but any other spatial distance metrics will work too.
Advantages of K-Means:
- Simple Model
- Easy to understand
- Assigns labels to data automatically
Disadvantages of K-Means:
- Determine K manually
- Converges to local minima
- Sensitive to outliers
- All items get labels.
Applications of Clustering
Clustering can have very wide applications in different domains, but the basic idea remains the same “Group data into its natural subgroups.”
- Customer Segmentation
- Market Research
- Exploratory Data Analysis
- Image Segmentation
These are, to name a few, but overall, any problem with an implicit group in it can use clustering.
For any questions and inquiries, visit us at thinkitive





I completely agree with the above comment, the internet is with a doubt growing into the a excellent number of important medium of communication across the globe and its due to sites like this that ideas are spreading so quickly. My best wishes, Alda.
I will surely foreward this post to all of my pals! Its very respectable and a very decent check out!
I think youve produced some genuinely interesting points. Not as well many people would truly think about this the way you just did. Im definitely impressed that theres so substantially about this subject thats been uncovered and you did it so nicely, with so a lot class. Very good one you, man! Seriously good things here.
Its such as you read my thoughts! You appear to know so much approximately this, such as you wrote the e book in it or something. I feel that you just could do with a few percent to power the message home a little bit, but other than that, that is wonderful blog. A fantastic read. Ill certainly be back.
Good web site! I truly love how it is easy on my eyes and the data are well written.Im wondering how I might be notified when a new post has been made.Ive subscribed to your feed which must do the trick! Have a nice day!
Hello! I just would like to give a huge thumbs up for the great info you have here on this post. I will be coming back to your blog for more soon.
Hi, Im following your blog from a long time now and read all the posts back to back when I saw it first timevery nice read!! Thank you!Regards
Right here is the perfect web site for anyone who hopes to find out about this topic. You understand a whole lot its almost hard to argue with you (not that I actually would want toÖHaHa). You definitely put a new spin on a topic that has been discussed for decades. Excellent stuff, just great!
I was excited to discover this website. I want to to thank you for your time for this wonderful read!! I definitely liked every part of it and i also have you book-marked to look at new things on your website.
Good post. I learn something totally new and challenging on blogs I stumbleupon every day. It will always be interesting to read through articles from other writers and use a little something from other sites.
Hello 😉 Thanks heaps for this indeed!… if anyone else has anything, it would be much appreciated. Great website Just wanted to say thanks and keep doing what you’re doing Thx & Regards!
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.