HL7 EHR Integration Guide

A few years back, I came across this whitepaper by IDC, The Digitization of the World: From Edge to Core, which made me think about IT and healthcare in a very different way. Apart from the 36% growth rate of healthcare data—the highest of all industries—it showed that the healthcare industry is getting more data-oriented.
Also, a significant rise in the use of wearable devices from 36.36% in 2022 simply cannot be ignored. Connecting this stat with the whitepaper findings, it was clear that healthcare IoT devices are major data contributors and play a pivotal role in patient care.
Having said that, the study also clearly indicated that unstructured data is dominant. Almost every other healthcare practice has chosen custom healthcare software for their practices, which often includes custom EHR software systems as well.
By the end of the whitepaper, it clearly stated that data isn’t just an IT concern, it is a strategic asset for healthcare practices. And this is what brought me the problem which is now a norm in healthcare practices – data sharing and system integrations.
Further trying to find the ‘WHY’ for this problem, I realized that unstructured data spread across the healthcare industry is one of the reasons. And interestingly, there is a solution for it, adhering to the healthcare data standards like HL7.
But since many practices have developed their own custom healthcare software systems, they need HL7 integration services to make their system a part of the connected healthcare ecosystem and landscape.
And that is exactly what we’re going to discuss in detail. So, without further ado, let’s deep dive into the intricacies of HL7 EHR integration.
Understanding HL7 Fundamentals & Message Structure
To help you understand HL7 fundamentals better, let me ask you a question.
‘How do you communicate with your friends?’ Obviously, language, right?
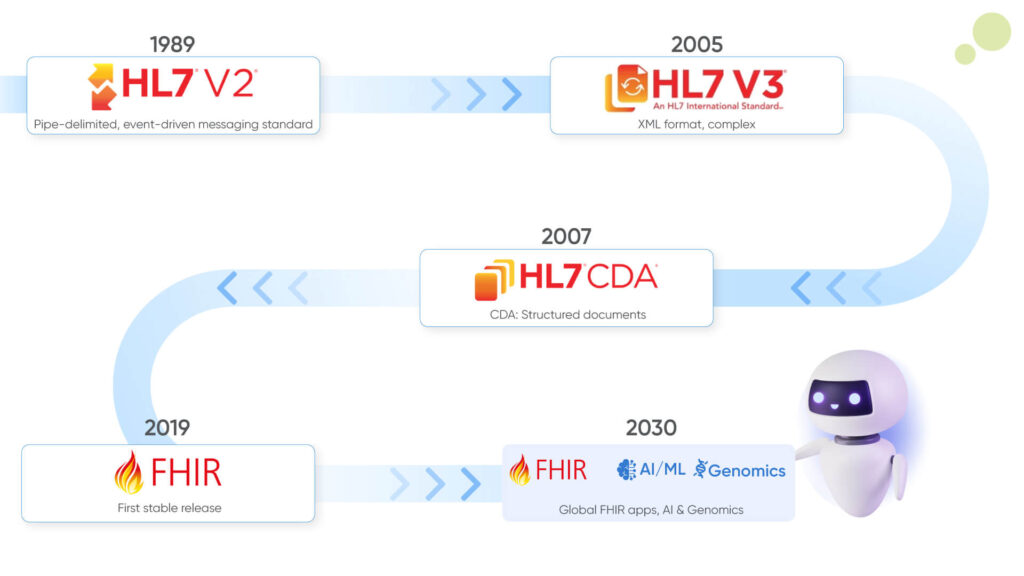
You can loosely translate HL7 as the communication language that the healthcare systems use to communicate with each other. To define HL7, it can be considered a data exchange standard for LIS, IIS, and EHR integrations, for example. Furthermore, just like our languages have evolved, these standards have also evolved, and newer versions of them have come up to serve different and other specific purposes. Let’s try to understand the different versions of HL7 briefly:
- HL7: HL7 stands for Health Level Seven, which is basically a set of international healthcare data standards for exchanging clinical and administrative health data. Furthermore, its widespread use and adoption have gained it a reputation as the universal healthcare IT language.
- HL7 v2: A newer version of HL7, which is used in over 80% of the healthcare interface structures worldwide and is used for exchanging data like lab results and patient admissions. The data stored with HL7 v2 guidelines are segmented into distinct fields like patient identification, clinical orders, etc. And typically, a message in HL7 v2 has a three-character string identifier such as ACK, ADT, RSP, etc.
- HL7 v2.x: Essentially, HL7 v2 and HL7 v2.x are the same standards, but HL7 v2.x is more compatible with a variety of systems, and it represents a family of systems that are all part of the v2 standard, and it is backward compatible, which we will discuss further in this blog. On the other hand, HL7 v2 refers to a specific version of the HL7 standard.
- HL7 v3: This version of HL7 is built on the foundational model of the Reference Information Model, aka RIM. It basically defines a set of abstract data concepts and builds its relationship with the core vocabularies of healthcare information in HL7. Despite being more robust, its backward incompatibility has made it a less popular option for healthcare organizations.
- CDA Framework: Also known as the Clinical Document Architecture framework, it is a standard framework for creating clinical documents. It is because of CDA that we are able to read healthcare reports.
NOTE: Backward compatibility is nothing but the ability of the newer versions of the HL7 messaging standards to work with other systems and data. Meaning a system using a newer version of HL7 would be easily able to communicate with the systems using an older version of HL7.
Core Message Components & Structure of HL7 Standards
Core message components and structure are two different things, and together they help in organizing the healthcare data in a way that is efficient for interoperability. Furthermore, it can be broken down into core message components and structure. Now, let’s break down the core message components for better understanding:
- Segment: Segments are the fundamental building blocks of an HL7 message; which each segment contains specific categories of information such as patient identification, visit details, etc. If you see an HL7 message, then you can easily identify the segments as they can be identified by a unique three-character code known as the segment ID. For example, MSH is used for message headers, PID is used for patient identification, and NK1 is used for next of kin.
Note: If you are a coder, then every segment is separated by a carrier return character ‘/r’. Moreover, there are 120 standardized segments, and if you want to define a custom segment, then you can, but you have to then start the message with ‘Z’.
- Fields (Composites): Now, the segment can be further divided into fields, also known as composites, which hold individual data elements. These fields are separated by ‘|’ or pipe character, and depending on the message type, they can be a mandatory or optional field.
- Components and Sub-Components (Sub-Fields): Fields can further be divided into components and sub-components for more detail. Components can be separated by the caret character (^) and sub-components by the ampersand (&).
HL7 Message Structure
The HL7 messaging needs to be structured so that it can easily communicate with disparate systems. Typically, these messages are made up of one or more segments arranged in a specific order depending on the message type and trigger event, such as patient admission.
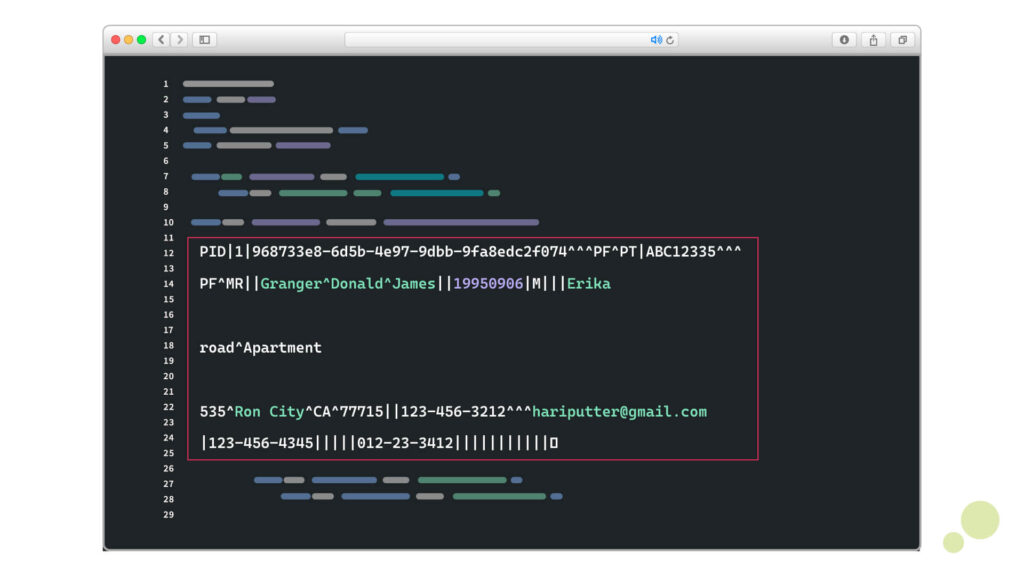
Example
PID|1|968733e8-6d5b-4e97-9dbb-9fa8edc2f074^^^PF^PT|ABC12335^^^PF^MR||Granger^Donald^James||19950906|M|||Erika road^Apartment 535^Ron City^CA^77715||123-456-3212^^^hariputter@gmail.com|123-456-4345|||||012-23-3412|||||||||||
If you take the above image, for example, then you can clearly see the three-character code, just as PID, which is separated by the delimiter character ‘|’. Along with that, you can identify the fields, components, and subcomponents in it and how they are separated by delimiter characters such as ‘\r’, ‘^’, and ‘&’, respectively.
Z-Segments & Customization Approaches
In the above example, the segments that you can see are all standard. However, there can be a segment that you want to custom add; then those segments are called Z-segments in HL7 messages. But here you might ask why ‘Z’.
Well, it is just a conventional practice to begin all the custom-defined segments with the letter ‘Z’. For example, ZBE, ZPD, etc. These segments lack a universal definition, which provides flexibility to include more data elements that are specific to a particular system, practice, region, or project.
You can use this HL7 message as an example for Z-segments – ZPD|1|MARRIED^Married|ENGLISH^English|NONSMOKER^Non-smoker||.
Message Flow & Exchange Patterns
If you’re still here, then you must have understood that HL7 messages are used to transfer healthcare data between systems by specific events, and that triggers the message flow. Now, typically a message flow involves sending, receiving, acknowledgement, and, if required, routing messages between healthcare applications.
On the basis of communication, there are two types of communication that can happen with HL7 standards – synchronous and asynchronous communication.
- Synchronous Communication: The best example of this type of communication can be seen in live chat, and that has been its unique identifier. In this type of communication, both the sender and receiver need to be active at the same time during message exchange. Also, in this type of communication, the response is typically immediate.
- Asynchronous Communication: Asynchronous communication differs from synchronous communication, where the response is not immediate. Meaning the sender can basically transmit a message without waiting for an immediate response. This can typically be seen in healthcare systems that are not connected at all times, but it does help improve the system’s scalability and fault tolerance.
Batch (Bulk) Vs Real-Time Processing
The messages, requests or instructions need to be processed for the healthcare systems to exchange information with each other. There are basically two types of processing which are batch processing and real-time processing.
- Batch Processing: Large volumes of data at scheduled intervals are collected and processed for complex computations. The typical type of processing in this type varies from a few minutes to days, depending on the volume of data.
- Real-Time Processing: As the name suggests, the processing happens almost immediately, which allows for timely clinical decisions with low latency.
Usually, your healthcare systems will be using a combination of data processing depending on the data that they need to collect, process, and share. For instance, real-time processing is used for patient monitoring, whereas for reporting, the system uses a batch process, as the data volume is complex and large.
Message Routing Considerations
Now, the word message routing must have bypassed your eyes quite a few times in the context of data sharing. Well, message routing refers to the process of directing HL7 messages to their appropriate destination, based on the message’s content and defined routing rules.
This routing depends on the message type and segments present in the message, whether it be EHR updates, lab systems, or billing. Depending on the content, it can transform HL7 messages into FHIR if required.
HL7 Message Structure Cheat Sheet
Download GuideTechnical Infrastructure for HL7 Integration
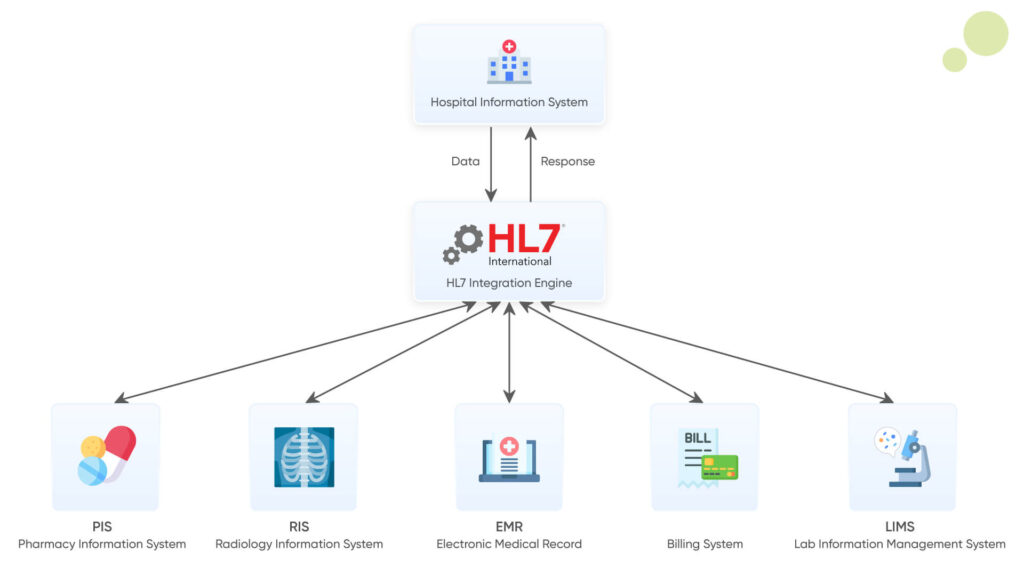
For establishing a connection between your healthcare system and the necessary EHR system, you need the connecting link, right?
To be honest, you not only need a connecting link but an entire ecosystem or infrastructure for your system to be able to share data with disparate healthcare systems from EHRs, to LIS, IIS, etc. So to get started, let’s start with the connecting link that sets the base for technical infrastructure for HL7 integration.
Interface Engine Options & Capabilities
While we are discussing the connecting link, the interface engine is that connecting link. Basically, it is a software that facilitates the exchange of data between your system with other healthcare systems using the HL7 standards.
And interestingly, there are different interface engines that you can choose from depending on the capabilities they offer. The table below will give you a better understanding of the options you get from the capabilities these interface engines provide.
| Interface Engine | Vendor | HL7 Version Support | Visual Interface | Customization | Cloud Support | Interoperability |
| Rhapsody | Lyniate | HL7 v2, v3, FHIR | Yes | JavaScript | Yes (Hybrid) | Yes |
| Corepoint | Lyniate | HL7 v2, v3, FHIR | Yes | GUI-driven, Limited code | No (On-Premise) | Yes |
| Mirth Connect | NextGen | HL7 v2, v3, FHIR | Yes | JavaScript | Yes | Yes |
| Cloverleaf | Oracle (formerly Infor) | HL7 v2, v3, FHIR | Yes | TCL Scripting | Limited | Yes |
| InterSystems Ensemble | InterSystems | HL7 v2, v3, FHIR | Yes | ObjectScript SQL | Yes | Yes |
Open-Source Alternatives for HL7 Integration
Most of the interface engines mentioned in the above table are paid, which can increase the cost of your EHR integration venture. To save some bucks in this venture, open-source HL7 interface engines have been widely adopted in building the HL7 integration infrastructure.
Apart from their cost-effective nature, these open-source alternatives also bring flexibility and strong community support. Here are some of the most popular options and their exclusive benefits:
- Mirth Connect: It is one of, if not the, leading open-source integration engines, which is known for its cross-platform compatibility. Along with that, this integration engine is very easy to use and offers robust support for HL7 message transformation, with routing and interface management.
- HL7apy: If you’re building a Python-based healthcare application, then this Python-based library design for HL7 message processing is your ideal solution.
- HAPI HL7v2: This open-source interface engine is a Java-based HL7 parser and API that allows parsing, encoding, and sending HL7 messages. It is usually used in clinical documents and laboratory messaging systems.
- JHL7: This is another Java-based open-source engine that offers comprehensive tools for managing and exchanging HL7 messages with monitoring and control features.
Cloud-Based Integration Platform
Unlike on-premise infrastructure, a cloud-based HL7 integration platform can be used to handle data exchange, data transformation, and storage. It has gained popularity lately for the key characteristics that it offers, like rapid deployment, scalability, cost efficiency, enhanced security, and compliance with modern protocol support.
However, despite the exclusive benefits, there are some drawbacks that you must be aware of like data residency, ongoing operational costs and reliance on network connectivity.
Build Vs. Buy Considerations
If you’ve made it till far, then you must be considering buying an integration platform at this point. And you’re not to be blamed. HL7 EHR integration is a complex process, and there are just too many considerations.
However, to help you make a better decision for either building or buying a pre-build technical infrastructure for your EHR integration, here are a few things that you must know.
You see, in this technical infrastructure, the transport method of messages and protocols is crucial for exchanging messages. While a pre-build infrastructure can offer you an instant solution, it fails to address the intricacies of your practice. This leaves you with one option: build your own technical infrastructure. But before that, you must know something about the transport methods and protocols.
Transport Methods & Protocols
Now, HL7 messages are typically transmitted over TCP/IP networks using various transport protocols tailored to achieve interoperability for your healthcare software systems. Some of the key approaches in this include:
- MLLP (Minimal Lower Layer Protocol): Since HL7 v2.x messages are typically transmitted over TCP/IP, MLLP has become a standard protocol for message transmission. It has been widely used in hospital LAN environments for real-time information exchange between EHRs, labs, and radiology systems.
- Web Services: This type of approach follows a more traditional way of message delivery where exchange happens over HTTP/S with SOAP protocols. Moreover, the messages are XML-based and the protocol allows bi-directional messaging with legacy system support.
- RESTful APIs (FHIR): Modern HL7 integration leverages RESTful web services with HL7 FHIR protocols and uses HTTP methods to interact with healthcare data resources in JSON or XML format. The major advantage of using this approach is that it offers a minimalist design with a stateless interface, which is ideal for mobile and web applications.
File-Based Transfer Mechanisms
Remember the batch processing we talked about earlier? A file-based transfer mechanism is used for that and is one of the foundational methods of HL7 EHR integration. In this, the messages are written to files and exchanged between systems via shared directories. Some of the common mechanisms in this include:
- FTP (File Transfer Protocol): FTP is widely used for transferring HL7 files between systems, especially for scheduled or non-real-time data exchange.
- SFTP/FTPS: SFTP is nothing but a secure extension of FTP that encrypts data during transfer and is considered safer as it ensures the confidentiality and integrity of data. SFTP uses SSH, while FTPS uses SSL/TLS for secure communication. In modern integration approaches, this is considered to be more secure and reliable.
In HL7 integration, security is something that cannot be ignored, given the sensitive nature of the healthcare data. While HL7 v2.x does not provide native encryption, external measures must be implemented, such as:
- Encryption: TLS/SSL is used for encryption.
- Authentication: Mutual authentication is employed with role-based access control and multi-factor authentication.
- VPN/SSH Tunnels: These are added for additional security, especially where the transfers happen over a public network.
However, given the constantly evolving nature of technology, and healthcare can lead to unreliable HL7 integrations. That is why it is important to continuously monitor and manage the HL7 EHR integration.
Message Tracking & Logging
Traceability, compliance, and troubleshooting are some of the core features of a reliable and effective HL7 EHR integration. Typically, integration engines and modules log all HL7 messages from informational to error events and even warnings to a centralized service log. These logs can then be dynamically organized by variables to make it easier for the system to locate and review.
Error Handling & Alerting
It is also a possibility that the system is not able to track the particular data in the system. And that is why error handling and alerting are required. Error handling in HL7 EHR integration typically involves detecting, logging, and responding to processing failures, communication issues, or malformed messages.
These systems can be configured to automatically route error alerts to specific components so that they can be rapidly identified and resolved with minimum data loss and downtime.
Implementation Planning & Development Process
The healthcare HL7 EHR integration landscape is as complex as the healthcare industry itself. And to ensure the accuracy in healthcare data transfer, you need to ensure that everything is just pitch perfect, and the start of that begins by understanding the scope and critically analyzing your requirements.
This not only becomes the first stage of HL7 EHR integration but also sets the stepping stone for the development phase. So, let’s start with the very first stage of the HL7 EHR development process:
Scope & Requirement Analysis
As discussed earlier, this phase in the development process is where you define the project goals, limitations, and expectations. In this case, you define what you want to achieve with HL7 EHR integration, for example, lab orders, EHRs, ADT messages, discharge summaries, etc.
In this process, you need to take into account all the stakeholders, like in-house IT professionals, clinicians, vendors, staff members, administrators, etc. By taking them into account, you can gather all the technical and business requirements so that you can fill the gaps in the system by connecting your healthcare software systems with EHR systems or other systems.
On top of that, it is at this stage where you identify the systems and the departments that are involved, and most importantly, the data that you want to exchange.
By the end of this stage, you must be able to create a detailed requirement document outlining objectives, timelines, and by when you will establish a connection with other disparate systems with HL7 EHR integration.
Integration Point Identification
Once you have defined the scope and requirements of HL7 EHR integration, you then need to determine where and how the systems will connect and exchange data with each other. And the very first step in this is to identify all the integration points.
The best way to do that is to map all the systems that you want to communicate with such as EHRs, LIS, RIS, billing systems, etc. Once that is done, then identify the source in the target system for HL7 messages. Once you have identified it, define interface endpoints and the data flow directions from that system into your system. This will help you in building an architecture that shows data exchange points and system interactions.
Message Type & Content Requirements
After the HL7 EHR integration architecture is designed, you get into the intricacies of the technical landscape. You see, you want to exchange information between your system and other disparate systems, but what information? Well, this is where you specify which HL7 message types are needed and what data they must contain.
To simplify, at this stage you ensure correct messaging standards are used for establishing integration so that the data fields meet clinical and operational needs. Remember the segments and field-level requirements we discussed earlier in this blog? Well, it is at this stage where you define that and align it with the corresponding systems.
And in just case the standard segments are insufficient, you validate the use of custom Z-segments.
Workflow & Process Mapping
Now, just like the patient journey from administration to clinician and back to administration again, it happens in a particular flow right? And holding data as a reference point in the entire workflow, you need to align the dataflow with both clinical and administrative workflows. By workflows and process mapping you can ensure that the integration supports real-world workflows like order entry or result delivery, etc.
The first step in this is to document the current workflow and the future workflows so that everything runs smoothly and parallel with each other. On top of that, by identifying data entry points and automated triggers, you can validate message timing and reduce dependencies.
Volume & Performance Considerations
The healthcare industry is always unpredictable and it can experience heavy patient flow at any time. That is why you need to ensure the system is able to handle expected and peak message loads without delays or data loss. And surprisingly you need to plan some aspects of it beforehand.
For instance, you need to estimate message throughput per interface, like ADT, ORU, SIU, etc. Then assess the time taken for message retrieval, especially for time-sensitive messages like ADT.
Apart from that, to improve performance of your HL7 v2 integration or HL7 v3 EHR integration, you need to consider database performance, network bandwidth and hardware specs.
Development & Configuration Approach
If you’ve been hanging in till now, then everything you did prior to this is just part of the planning, and at this stage, you actually code. Well, not technically, as one step prior to this needs to be covered.
You see, before you start development, you actually need to determine how the interfaces of your system and integrated system will be developed, tested, and deployed. The best way to do this is to sit with your development team and decide everything prior to this.
Here are some best practices that you can consider for this:
- It uses a modular interface design, as it has separate message handling, transforming, and routing aspects.
- Depending on the interface engine, your development team can choose between graphical tools or a code/scripting-based customization approach.
- Implement version control for interface configurations.
- Standardize naming conventions, error handling routines, and logging mechanisms.
Interface Specification Documentation
Once the integration bridge is developed, you need to document how each interface behaves and interacts with systems. To give you an idea of what you need to document, it varies from HL7 message types, segments, triggering events, field-level mapping, data type expectations, communication protocols, etc.
This documentation is essential for developers to coordinate and refer this for future references. On top of that, it plays a critical role in maintaining the HL7 EHR integration bridge.
Message Mapping & Transformation
By this time, you must have understood that every system stores the information in a way that is convenient for it. This is why when you draw out certain connections with the systems, the message needs to be translated so that not only your system but also it should be understood.
To achieve this your system must be capable of handling field-level mapping between HL7 and EHR data models. You also need to manage code system translation like LOINC, SNOMED and local codes. Along with that, you also need to account for custom Z-segments or extensions used by the vendors.
Last but not least, all transformations are logged for auditability and debugging.
Rule & Filter Configuration
Your healthcare practice consists of many different departments, and they all deal with different types of data. However, not everyone in your practice needs to access all types of data, and if it is accessible, then it might even compromise the fundamental rights of the patient. And that’s exactly why you need to implement a rule and filter configuration into your practice.
After this, the system will route messages to the particular facility or department. Along with that, it will also filter the test messages, duplicates, and invalid messages, saving both time and effort. To make the process more accurate, conditional logic should be applied to save unnecessary data collection. For example, by applying conditional logic, the system can only process lab results for admitted patients.
Test Message Development
Once your system is ready, the next thing that you need to do is test message development in HL7 v2 or HL7 v3 or FHIR format that are similar to real-world clinical data. This is to test your system’s reliability to validate the structure, data mapping capabilities and transformation in the integration engine. While developing this ensure that you cover different message types from ADT, ORM, ORU, etc.
Also, before going live or deployment, develop a structured plan outlining HL7 interfaces and integrations, and include stakeholders, timelines, and success criteria of the integration bridge. Here are some of the necessary tests that you must conduct:
- Unit Testing of Transformation: Test the logic applied in this that is used to transform HL7 messages, such as mapping fields and conversion formats from HL7 v2 to FHIR.
- End-to-End Testing Approaches: Validate the full integration workflow from data entry in your healthcare system to processing of that information in the integrated system. It is confirmed that the messages are routed correctly and transformed as expected.
- Validation Against Specification: This type of testing is done to ensure that the HL7 messages comply with national and organizational implementation guides. It is used as a validator to check syntax and semantics and plays a critical role in achieving interoperability.
- Performance and Load Testing: These tests are done to check if the HL7 interface engineer and systems are able to handle large volumes of messages under stress. This will help you detect potential bottlenecks and identify any risks of data loss, latency, or system crashes during high-load situations.
Clinical Use Cases & Workflow Integration
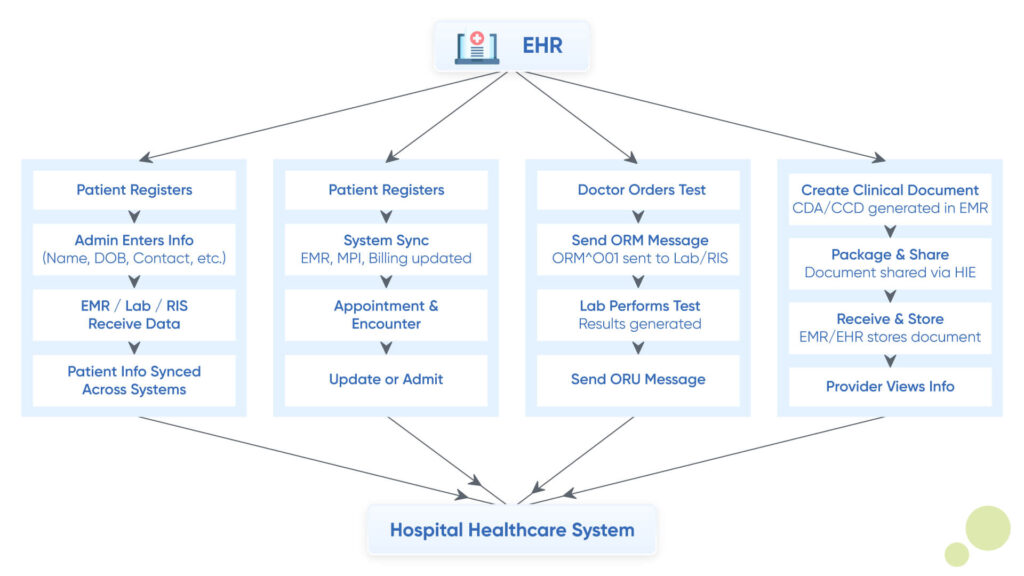
HL7 EHR integration has exclusive benefits that can significantly improve both clinical and administrative processes of your practice. However, you might just know some of the surface benefits, but the clinical use cases and workflow integration are something that you must explore to harness the true potential of HL7 EHR integration. Let’s have an overview of the clinical use cases of HL7 EHR integration, starting with ‘Patient Demographic Synchronization’:
Patient Demographic Synchronization
With HL7 EHR integration, you can synchronize the patient’s core identity data across all the healthcare systems that are connected in your network. Patient identity data includes name, date of birth, address, gender, etc.
The clinical use case of this is that from the front desk, where the patients register themselves, the information is instantly available at all the connected systems, such as labs, imaging, billing, etc. This can benefit your practice by preventing record duplication, ensuring accurate charting, and ensuring a smooth transition of care for the patients.
- ADT (Admission, Discharge, Transfer) Message Utilization: The core purpose of ADT messages is to communicate patient movement or their care journey within your connected healthcare systems or facilities. It benefits your practice by enabling real-time patient tracking and effective resource management.
- Master Patient Index (MPI) Integration: An MPI is a centralized database that contains a unique identifier for every patient across multiple systems and facilities. Its use case in your practice is that it enables retrieval of patient health information seamlessly and in real-time.
Now that we’ve covered the patient data synchronization, let’s look at the different clinical and administrative workflows and how HL7 EHR integration can help you enhance them.
Registration & Encounter Workflows
This workflow is mainly about the creation and management of patient demographics and visit information. It is this workflow that defines the flow of information in your system and creates a foundation for downstream clinical and administrative systems. It helps in accurate registration and prevents duplication of records for proper linkage of orders and results. Also, it helps in the accurate sharing of information across the connected system, like labs, radiology, billing, and pharmacy.
Here are some aspects of this workflow that you must know:
- Patient Merge & Unmerge Workflows: When creating patient records manually, there is a high chance of records being duplicated. This process can not only create confusion but also stretch the care journey for patients. And this is where the patient merge and unmerge workflow comes into the picture. It not only involves managing duplicate patient records but also correcting the merges that happen by mistake. It plays a critical role in maintaining a clean Master Patient Index.
- Order & Result Management: Clinical orders from labs, radiology, or pharmacies are reported in their own way, which, when reporting back can be complex to understand. However, by integrating HL7 EHR with this workflow, whenever an entry is made, the data is then routed to ancillary systems like LIS, RIS where it is processed while being routed back to your system with correct match.
- ORM & ORU Message Implementation: ORM stands for Order Messages, and ORU stands for Observation Result Messages. These are some of the key HL7 messages that are used for managing orders and results in real-time across systems.
Lab & Diagnostic Order Workflows
Another crucial workflow for your practice is labs and diagnostic order. This workflow involves placing, transmitting and tracking labs and imaging orders from EHRs to external orders like LIS, RIS, PACS and back to the EHR system after receiving the results. Some of the HL7 messages used in this are ORM, ORU, and SCH/SIU.
Here are some of the considerations in this workflow that you must know:
- Result Delivery & Acknowledgement: This workflow refers to the way results from labs are processed and returned to the EHRs with received confirmation, aka acknowledgement. This acknowledgement of messages is done via ACK messages, and the results are delivered with discrete observations.
- Discrete Data vs. Document Exchange: Discrete data and document exchange are two common methods of result and documentation exchange. While one is structured data and supports automated alerts, the other is unstructured reports, which are sent via HL7 v3.
- Clinical Documentation Exchange: During every care episode, certain documentation is made, such as physician notes, discharge summaries, consult reports, etc. C-CDA, FHIR, or MDM messages are used to share these messages. Using these documents can be correctly shared with patients and their visits, along with documenting external care received by patients at other facilities.
Document-Based Exchange Workflows (CDA, C-CDA)
Along with the exchange of results and orders, some documents also need to be exchanged between providers, patients, and even healthcare facilities. This exchange involves sharing complete clinical documents between EHR systems using HL7 CDA or C-CDA standards.
Here are some considerations in this that you must know:
- CDA Implementation Considerations: While implementing CDA-based workflow into your system some considerations like standard alignment, template usage, version control, data transport methods must be considered.
- Structured vs Unstructured Content: CDA documents contain both structured and unstructured data. To help you understand the considerations in this better, refer to the diagram below:
| Content Type | Description | Use Cases |
| Structured | Encoded using standardized templates (e.g., LOINC-coded labs, SNOMED CT) | Data extraction, clinical decision support, population health |
| Unstructured | Free-text narratives, often in <text> sections | Human readability, detailed documentation |
| Hybrid | Most C-CDA documents contain both, for human and machine use | Broad interoperability |
- Discrete Data Extraction Approaches: One of the key aspects of workflow integration and analytics is extracting actionable insights from CDA documents. That is why choosing the right approach becomes extremely critical. Some of the approaches that you can use are template-based parsing, natural language processing, FHR conversion, or Business rule engines. All these approaches have their own distinct benefits, and choosing the one that suits your practice is suggested.
Security, Compliance & Data Integrity
The sensitive nature of the data that your system will deal with makes it an ideal target for cyberattacks. This can compromise the fundamental rights of the individuals, which can also impact your practice’s credibility. Here, ensuring data security, compliance, and integrity is extremely necessary, and here are some considerations that you must undertake:
Security Considerations for HL7 Integration
The major part of HL7 integration, whether it be HL7 v2 integration or HL7 v3 integration, involves the exchange of patient data across multiple systems. That is why implementing robust security measures is essential to prevent breaches, unauthorized access, and data manipulation. Addressing these major concerns in HL7 EHR integration, here are some major considerations:
- Transport Layer Security (TLS) Implementation: TLS is one of the primary protocols for the encryption of HL7 messages when they are in transit. It basically prevents interference, eavesdropping, and man-in-the-middle attacks. However, for this, you need to rely on X.509 certificates for authentication of server endpoints. To add another layer of security, it is suggested that certification be obtained on both the systems that are involved in data sharing.
- Authentication & Authorization Approaches: While the messages are being encrypted, it can be difficult for the systems to verify the identities, etc. In such cases, you can use X.509 certificate-based authentication, which relies on MSH-3|MSH-4 segments to identify devices. Furthermore, this approach ensures strong, cryptographic identity verification. You can also use other options, such as OAuth 2.0 tokens or role-based access control.
- Audit Logging & Tracking: As the systems will be constantly exchanging information with different systems, they need to keep detailed logs of all the transactions. A comprehensive audit of these exchanges can help identify suspicious activities, etc. Other than with Security Information and Event Management (SIEM), your system can enable real-time monitoring, which can detect threats beforehand, such as unauthorized access or data exfiltration attempts.
PHI Protection Measures
When your health information is created in your EHR, there is certain information that can identify you as an individual. This information is called PHI or Protected Health Information. The PHI information is usually protected under HIPAA regulation and plays a crucial role in patient privacy. On that note, here are some PHI protection measures that you must implement:
- Regulatory Compliance Requirements: Your HL7 integration must comply with all the necessary regulatory frameworks, such as the HIPAA security rule, which covers administration, physical, and technical safeguarding for PHI. Other than that, you must also adhere to the breach notification rule and business associate agreements.
- HIPAA Implications for Message Exchange: HIPAA plays a critical role in the protection of PHI. That is why it requires you to transmit messages between systems using encryption and secure transport mechanisms. Along with that, you are also required to implement access controls, maintain auditability, and manage vendors effectively.
- Information Blocking Rule Considerations: This rule is one of the cornerstones of the 21st Century Cures Act, where healthcare providers cannot unreasonably interfere with the access, exchange, and use of electronic health information.
- Audit Trail Maintenance: Keeping an audit trail can be extremely useful as it can help you identify any loopholes in your security and also make you aware if anyone has breached it.
Data Integrity & Validation
Data integrity and quality form the foundation of HL7 EHR integration. While it appears to be very simple and easy steps at the start, it is quite a complex process that involves a combination of validation rules, error handling, monitoring, and reconciliation processes. So, without further ado, let’s have a look at a few considerations:
- Data Integrity & Validation: A major process involves mapping and normalizing data from various sources such as EHRs, labs, devices, etc., to conform to HL7 standards. This allows the systems to interpret and process the data accurately. Also, both sender and receiver systems should validate data against HL7/FHIR specifications both before and after transmission.
- Message Validation Rules: HL7 engines and validation tools allow you to define rules for each message field or component. Along with that, if you have a specific workflow, then you need to validate rules in accordance with those criteria, so that your system can handle complex validation scenarios.
- Error Handling & Exception Management: An effective HL7 interface includes mechanisms that help detect, log, and handle incomplete messages. It not only prevents the interface from crashing and data loss but also improves patient safety.
- Data Quality Monitoring: The quality of data is everything that makes integration so accurate. That is why you require monitoring throughout the lifecycle from entry to access. Real-time monitoring tools can be used to identify inconsistencies, duplicates, and missing data.
- Reconciliation Process: The process of aligning data between internal systems and external sources such as labs, vendors, and devices plays a crucial role in ensuring consistency, accuracy, and completeness of data. That is why regular reconciliation is required.
Conclusion
If you’ve made it till here, then you must have made up your mind about HL7 EHR integration. Its guide took a little longer due to its complex nature and intricate technicalities. However, for your system to achieve interoperability, it appears to be the cornerstone that redefines everything.
I hope that this blog serves you as a complete guide for implementing HL7 integration and help you in building the ideal bridge between your and other desperate healthcare software systems. And if you still don’t know where to get started, then please click here and we’ll help you in building the HL7 EHR integration bridge for your custom healthcare software system.
Frequently Asked Questions
HL7 v2 is a text-based messaging standard that focuses on point-to-point communication between disparate healthcare systems. On the other hand, HL7 v3 is a more recent and complex messaging standard that follows an XML-based approach, where the emphasis is on standardized data models and RIM for greater semantic interoperability.
HL7 is a messaging standard with complex, often proprietary encoding that is suitable for batch processing and legacy systems. FHIR, on the other hand, is a modern, web-based standard using RESTful APIs and common data formats like JSON with greater flexibility and real-time data exchange.
Here are some of the most common HL7 message types used in EHR integration:
- ADT – Admit, Discharge, Transfer
- ORM – Order Message
- ORU – Observation Result
- MDM – Medical Document Management
- ACK – General Acknowledgement
Some of the popular interface engine options for HL7 integration are:
- Corepoint Integration Engine
- Infor Cloverleaf
- Iguana Integration Solutions
- Rhapsody Integration Engine
- Mirth Connect
- HAPI HL7v2
Effective testing for HL7 interfaces involves a combination of methods. Starting with message syntax and structure validation against HL7 healthcare data standards. Conducting a functional test with realistic data scenarios, including edge cases, after which we perform integration testing across connected systems and ensuring data accuracy and workflow adherence. Last but not least, using monitoring tools for real-time analysis and error tracking.
The complexities arising from different HL7 versions and vendor-specific implementations are some of the most common challenges. Other than that, inconsistent data semantics and accurate data mapping between disparate systems pose other significant hurdles. Data security, alignment of integration with clinical workflows and cost management are ever ongoing concerns.
After implementing HL7 interfaces continuous monitoring for errors and performance is required. Also, regular testing after system updates and changes is required to ensure data integrity.
Security measures for HL7 integration include strong encryptions for data in transit, robust authentication, strict access controls, regular security audits and vulnerability assessment along with logging and monitoring.
High-volume message processing is done by employing techniques like message queuing for buffering, parallel processing to distribute the load, and efficient data storage solutions. Optimize message parsing and validation, and consider using a robust integration engine designed for high throughput. Monitoring and scaling capabilities are also crucial.
The HL7 integration team requires strong technical skills in HL7 standards, data mapping, and integration engines. Along with that, effective communication and collaboration with the clincal team with a problem solving appraoch is required to achieve seamless and secure data exchange.
Estimating HL7 integration costs involves assessing the number and complexity of systems, data transformation needs, interface development, testing, deployment, and ongoing maintenance. Consider vendor fees, internal resource allocation, and potential regulatory compliance efforts for a comprehensive budget.
For HL7 integration, essential documentation includes interface specifications (detailing message structure, data mapping, and communication protocols), data dictionaries (defining data elements and formats), and test plans (outlining testing scenarios and expected outcomes). Security and compliance documentation are also crucial.
Custom “Z-segments” in HL7 integration provide flexibility for transmitting data not covered by standard segments. However, they introduce complexity as they are locally defined and lack universal understanding. This necessitates custom parsing logic and can hinder interoperability if not well-documented and coordinated between systems.
Use interface engines or middleware for message transformation and routing between different HL7 versions. Employ data mapping tools to align disparate data structures. Thorough testing and validation are crucial to ensure accurate data exchange. Consider upgrading legacy systems or adopting newer HL7 versions like FHIR for better interoperability.
HL7 integration implementations are significantly impacted by regulations such as HIPAA (in the US) for data privacy and security, and potentially GDPR (in Europe) if applicable. These mandate secure handling, transmission, and access control of patient health information exchanged via HL7 standards. Compliance with these regulations is crucial.




