EHR Data Mapping: Solving Complexity in Multi-System Environments
How many errors are there in an EHR on average?
In a test of 401 electronic health documents using HL7 validation, almost 86.3% of the documents contained an average of 4.9 errors per document, according to the National Library of Medicine. Furthermore, the majority of these errors were data completeness and syntax-related issues.
These documents generate an average of 53.1 data-quality alerts per document. This shows how delicate the clinical-data mapping process is. Interestingly, all these systems claimed they have standard-compliant exchanges.
This is the reason why studies show that more than 50% of EHR development projects have failed. And some of the major reasons cited for this were inaccurate or mis-mapped patient histories.
Upon digging deeper, the problem that linked all these errors together was that the EHR systems simply fail to communicate with each other. As their data language was the major barrier that simply made their language gibberish to each other.
So, as a provider, you might be finding a solution for this, right?
Well, there is, in the form of EHR data mapping. For your EHR system, it acts as a translation layer for interoperability, giving your systems the ability to understand data stored in other systems and make sense of it.
And this is the reason why data mapping has become a cornerstone in enabling scalable EMR data integration. Moreover, with the rise of AI-driven systems in healthcare, data mapping is today used for solving complexities in multi-system environments.
So, without further ado, let’s understand the intricacies of data mapping in healthcare and how it can be beneficial for your healthcare practice.
What is EHR Data Mapping in Healthcare?
Let’s start with the basics for some of the readers who might have been new to healthcare IT terminologies. So, in simple terms, EHR data mapping is the process of aligning, translating, and connecting data elements between different healthcare systems so that they understand the data and make use of it.
Now, in the EHR integration process, some of these terminologies might appear to be of similar meaning. However, there can be a striking difference between them. Refer to this table for a better understanding:
| Aspect | Data Mapping | Data Integration | Data Transformation |
| Definition | Defines how data fields from one system correspond to another | Connects different systems to enable data exchange | Converts data into a required format, structure, or unit |
| Primary Focus | Relationships between data elements | System connectivity and data flow | Data format and structure changes |
| Key Purpose | Ensure correct interpretation of data | Enable seamless communication between systems | Make data usable and standardized |
| Example | “BP_sys” → “Systolic Blood Pressure” | EHR connected to a lab system via API | Converting mg/dL → mmol/L |
| When It Happens | Before or during data exchange setup | During real-time or batch data exchange | During data processing or transfer |
| Dependency | Required for accurate transformation and integration | Depends on mapping and transformation | Relies on mapping rules to apply correct changes |
But here you might ask, how is clinical data mapping and interoperability interconnected? Well, in the clinical context, it helps healthcare organizations retain the true meaning of the clinical data across systems.
Data mapping ensures that accurate patient records are maintained across systems. The aftermath of this can transform your practice by allowing you to make safe clinical decisions, removing duplicated or inconsistent data, and most importantly, supporting care continuity across providers.
The Use of AI in EHR Data Mapping
Traditionally, the process of data mapping has been manual, and the chances of making an error were quite high. Here, AI-driven approaches can automate important aspects such as automated field matching, semantic mapping, and normalization of data so that your system can understand and make use of it. On top of that, a few of the practices are even using it to detect duplicate records and remove them from the records.
How EHR Data Mapping Works in Healthcare Systems
If you go by the definition, then you know that data mapping is a process. However, what is that process, and how does EHR data mapping work in healthcare systems?
Well, let’s find out.
So, to understand the process better, think of EHR data mapping as a layered process so that both the structure and meaning of the data are preserved across systems.
Starting with the first step of the process:
- Structural Mapping: This type of mapping is simple, where you match a field from one system to another. For instance, it handles differences in field names, data formats, or data types. This way, it forms the foundation of data mapping, as it gives the system the ability to place the data correctly in the relevant place.
- Semantic Mapping: This mapping, on the other hand, refers to retrieving the meaning of the data across systems. It aligns clinical concepts from two systems, and some of the standardized terminologies used in this are SNOMED CT, ICD-10 codes, LOINC, etc. This mapping ensures that clinical accuracy is maintained across records.
In simpler terms, structural mapping ensures where the data goes, whereas semantic mapping ensures what the data means.
EHR Data Mapping Process: End-to-End Workflow
The EHR data mapping process consists of five major steps. Here is a brief blog that will help you understand what activities are involved in each step and what outcome is achieved from each process:
| Step | Stage | What Happens | Key Activities | Outcome |
| 1 | Extraction | Data is pulled from source systems | APIs (FHIR), HL7 messages, databases, flat files | Raw data collected from multiple systems |
| 2 | Normalization | Data is standardized into a consistent format | Format alignment (dates, units), data cleaning | Clean, uniform data ready for mapping |
| 3 | Mapping | Data fields and meanings are aligned | Structural + semantic mapping, terminology alignment | Data correctly matched across systems |
| 4 | Validation | Data accuracy and consistency are verified | Error checks, completeness checks, clinical validation | Reliable and accurate mapped data |
| 5 | Ingestion | Data is loaded into the target system | Data import into EHR, storage, indexing | Data ready for clinical use and workflows |
EHR Data Mapping for Multi-System Environments
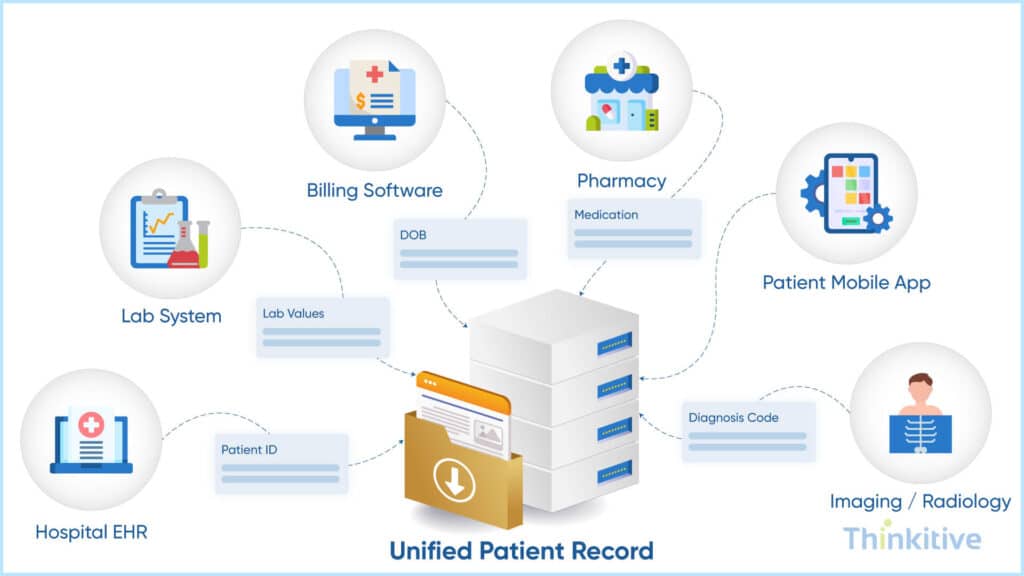
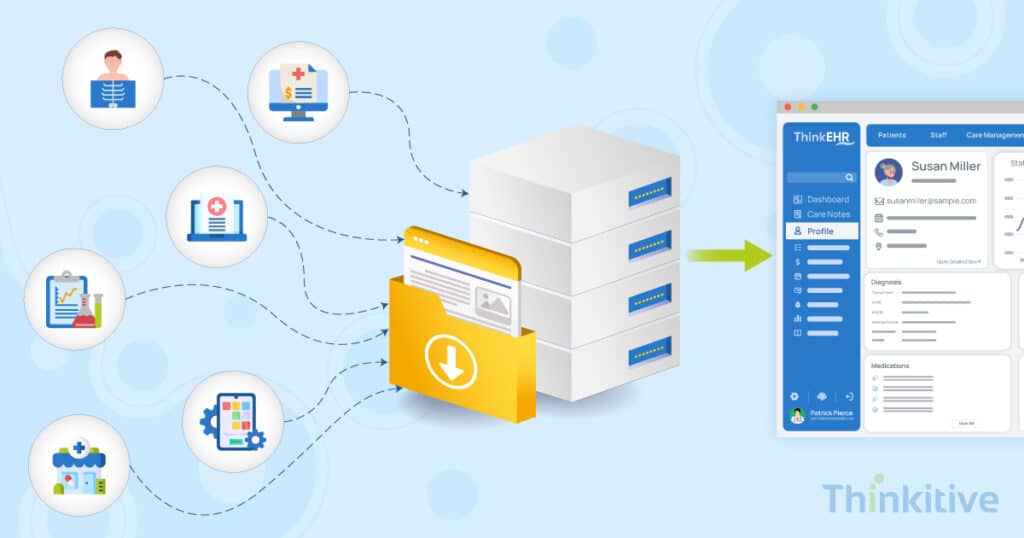
I know that I have been saying that data mapping is the process of matching the data fields from one system to another. But in real-world settings, do you really think that data flows between just two systems?
You see, your data flows from multiple EHRs, lab systems, imaging systems, RPM devices, billing platforms, and whatnot. Now, the challenge is that the same patient might be present in multiple systems, or the data in one of those systems might be incomplete, or the information might be stored in a different style. This slight difference can have a huge impact on your practice, right?
That is why EHR data mapping becomes more complex, especially in multi-system environments. The problem we discussed is the major obstacle in multi-system environments.
In such cases, your data mapping must identify such information stored in slightly different ways and merge all these records without losing accuracy.
Furthermore, it should be able to handle different coding systems. In simple words, it should translate codes across systems, preserve their meaning, and ensure consistency in reporting and decision-making.
- The Problem with Unit & Format Inconsistencies
Different systems store the same data in different formats or units. One of the most common examples of this can be seen in dates; while a system might store it in DD/MM/YYY, the other one might store it in MM/DD/YYYY.
Such inconsistencies can create mapping issues that can be critical or change the meaning of the data. And the best way to overcome this is by normalizing the data before starting the mapping process.
- AI-Driven Normalization & Conflict Resolution
Traditional approaches have struggled with managing multi-system complexity due to various reasons like scalability, variations, and continuous flow of data. Here, normalizing this data can be quite critical and at times even becomes time sensitive. In such cases, you can use AI to handle this complexity and intelligently normalize data based on units, formats, etc.
Moreover, it can even resolve the cross-system entity resolution and recover the semantic conflict, restoring the accurate meaning of the data stored in different systems.
Challenges in EHR Data Mapping & How to Solve Them
I might brag on and on about the challenges that you might face with EHR data mapping, but they would often go over your head. So let’s understand them better with their real-world impact and how you can solve them. Refer to the table below:
| Challenge | Description | Impact | Solution | Outcome |
| Semantic Mismatches | Different systems use different coding standards (ICD, SNOMED, LOINC) | Misinterpretation of clinical data | Standardization using clinical terminologies + FHIR | Consistent clinical meaning across systems |
| Missing / Inconsistent Data | Incomplete, duplicated, or conflicting patient data | Poor data quality and unreliable insights | Validation frameworks + data quality rules + MPI | Accurate and reliable patient records |
| Legacy System Complexity | Outdated systems with limited interoperability capabilities | High integration effort and fragile mappings | Middleware + API layers + gradual FHIR adoption | Seamless integration across old and new systems |
| Scaling Across Large Datasets | Increasing number of systems and data volume | Manual mapping becomes inefficient and error-prone | Automation + reusable mapping templates + governance | Scalable and efficient data mapping processes |
| Hidden Mapping Errors | Undetected inconsistencies during data exchange | Clinical risks and incorrect decisions | AI-based anomaly detection and real-time validation | Early error detection and improved accuracy |
Ensuring Data Accuracy & Integrity
The success of your data mapping efforts relies directly on data accuracy and integrity. Given the impact it can have on your practice, it is important for you to ensure data accuracy and integrity. Here are some of the best ways in which you can ensure that.
- Source-to-Target Validation: Validate the source of the data from which you are fetching and while doing so, also validate the target, so that it can reach its right system.
- Design Lineage & Audit Trails: Ensure the data you are receiving into your system can be tracked right to its original source. And along with that, conduct audit trails so that you know what is happening in your system.
- Error Detection & Correction: During all these processes, you are bound to encounter many errors. While you address them, correct them then and there so that the next processes are streamlined and accurate.
- Compliance Considerations: Like EHR development, data mapping also has compliance considerations that you must adhere to. These compliances might be specific to data mapping, but play a huge role in normalization and cleansing.
These are some of the ways in which you can ensure data accuracy and integrity. Furthermore, you can also use machine learning models for continuous validation of data and ensure that the data quality is always accurate.
Best Practices for Scalable EHR Data Mapping
If you have made it this far, then you must know some of the best practices for scalable EHR data mapping.
- Standardized Data Formats & Coding Systems: The one thing that every page about EHR data mapping will say to you is to use standardized data formats and coding systems. This is because it makes your system understand data better.
- Design for Multi-System Environments: When data mapping, design the module for a multi-system environment. This is one of the best practices because in healthcare, data hardly flows through just two systems.
- Use ETL/ELT Strategically with Data Mapping Pipelines: Depending on infrastructure, data characteristics, and compliance, use the Extract, Transform, Load or Extract, Load, Transform.
- Implement Governance & Monitoring: Have a mechanism in place that allows you to monitor data mapping pipelines and ensure that the performance is top-notch.
Conclusion: The Foundation of Connected Care
EHR data mapping is not something that you implement once and is not set forever. In fact, it is a continuous process that gives you a strategic capability to your system. Moreover, it is important for your practice to ensure your system’s data sharing capabilities are accurate, scalable, and governed.
Last but not least, leverage AI-driven data mapping so that the integrity of the data is intact and also accurate. On that note, if you’re looking to build your EMR data integration strategy, then assess your data quality and get consultation from our experts here.
Frequently Asked Questions
The primary goal of EHR data mapping is to ensure that data exchanged between different healthcare systems is accurate, consistent, and clinically meaningful. It aligns data fields, formats, and terminologies so that information can be interpreted correctly across platforms.
In the broader context of data mapping in healthcare, this process enables seamless interoperability, reduces errors, and supports better clinical decision-making by ensuring that patient data remains reliable throughout the exchange.
Semantic interoperability focuses on preserving the meaning of clinical data, while structural mapping ensures that data is placed in the correct fields across systems.
In clinical data mapping:
- Structural mapping defines where the data goes
- Semantic interoperability ensures what the data means remains consistent
Understanding how EHR data mapping works in healthcare systems requires both layers—because accurate data placement without correct meaning can still lead to clinical misinterpretation.
The most common challenges in EHR data mapping for multi-system environments include:
- Semantic mismatches across coding systems
- Missing or inconsistent data
- Legacy system limitations
- Scaling mapping across large datasets
- Hidden mapping errors
These issues highlight the importance of addressing challenges in EHR data mapping and how to solve them using standardization, validation frameworks, automation, and AI-driven approaches.
Standards like LOINC and SNOMED CT play a critical role in healthcare data mapping by ensuring that clinical concepts are represented consistently across systems.
They enable:
- Accurate semantic mapping
- Standardized clinical interpretation
- Improved interoperability
Without these standards, the EHR data mapping process would be prone to ambiguity and errors, especially in complex clinical environments.
AI and Machine Learning can significantly enhance clinical data mapping, but they cannot fully replace human oversight.
They help by:
- Automating field matching
- Identifying patterns and anomalies
- Improving mapping accuracy over time
However, due to the complexity of healthcare data mapping, especially in clinical contexts, expert validation is still essential. AI is best seen as an augmentation tool, not a complete replacement.
Data mapping defines how data fields align between systems, while data migration involves moving data from one system to another.
In the EHR data mapping process:
- Mapping ensures data is correctly aligned and interpreted
- Migration executes the transfer of that mapped data
Both are essential, but mapping is a prerequisite for successful migration in any healthcare system.
Ensuring data integrity during large-scale transformations requires a combination of:
- Robust validation frameworks
- Data quality checks (accuracy, completeness, consistency)
- Standardized mapping rules
- Continuous monitoring and auditing
In EHR data mapping for multi-system environments, maintaining data integrity is critical to avoid clinical risks and ensure reliable outcomes across systems.
EHR data mapping is the foundation of successful EMR/EHR integration because it ensures that data exchanged between systems is accurately aligned and meaningfully interpreted.
Without proper data mapping in healthcare:
- Systems may exchange incorrect or misinterpreted data
- Clinical workflows can be disrupted
- Decision-making can be compromised
Ultimately, effective healthcare data mapping enables true interoperability, making it a critical component of any integration strategy.




